Fast Counting in the Oracle Database with APPROX_COUNT_DISTINCT
This blog is part of the overall "10 Oracle Database Features That Fly Under the Radar" and explains what the APPROX_COUNT_DISTINCT function is and how its used. This feature isn't as flashy as some of the others in the overall post but is still great and is often overlooked.
What is APPROX_COUNT_DISTINCT
APPROX_COUNT_DISTINCT was added in oracle 12.1 and gives you approximate distinct counts using some clever algorithms. Instead of checking every single value, it uses statistical methods to estimate the count. This means we get queries that run dramatically faster while staying around about 3% of the exact count.
When to Use It:
-
Large datasets where exact counts aren't critical (think data warehousing)
-
Real-time analytics dashboards
-
Performance-sensitive reports
-
Data exploration and trend analysis
Quick Demo
The APPROX_COUNT_DISTINCT function gives you approximate distinct counts using statistical methods. It trades perfect accuracy for better performance. We can see it with an e-commerce example.
Being this is a small demo, we will see small improvements in speed
Note this is going to create and populate a table with about 10 million rows. There are screenshots below if you would like to look at the output rather than test it yourself
-- Create our sample tables
CREATE TABLE web_visits (
visit_timestamp TIMESTAMP,
visitor_id NUMBER,
page_url VARCHAR2(200)
);
-- Populate with 10M rows instead of 1M
BEGIN
FOR i IN 1..10 LOOP
INSERT INTO web_visits
WITH data AS (
SELECT
SYSTIMESTAMP - NUMTODSINTERVAL(DBMS_RANDOM.VALUE(0, 90), 'DAY')
- NUMTODSINTERVAL(DBMS_RANDOM.VALUE(0, 86400), 'SECOND') as visit_timestamp,
TRUNC(DBMS_RANDOM.VALUE(1, 1000000)) as visitor_id,
CASE MOD(LEVEL, 5)
WHEN 0 THEN '/products'
WHEN 1 THEN '/home'
WHEN 2 THEN '/cart'
WHEN 3 THEN '/checkout'
ELSE '/category'
END as page_url
FROM dual
CONNECT BY LEVEL <= 1000000
)
SELECT * FROM data;
COMMIT;
END LOOP;
END;
/
-- Create indexes for better performance
CREATE INDEX web_visits_ts_idx ON web_visits(visit_timestamp);
CREATE INDEX web_visits_visitor_idx ON web_visits(visitor_id);
COMMIT;We can now look at the exact vs approximate counts
-- Let's compare exact vs approximate counts
SET TIMING ON;
-- Exact count (slower)
SELECT COUNT(DISTINCT visitor_id) as exact_visitors
FROM web_visits;
-- Approximate count (faster)
SELECT APPROX_COUNT_DISTINCT(visitor_id) as approx_visitors
FROM web_visits;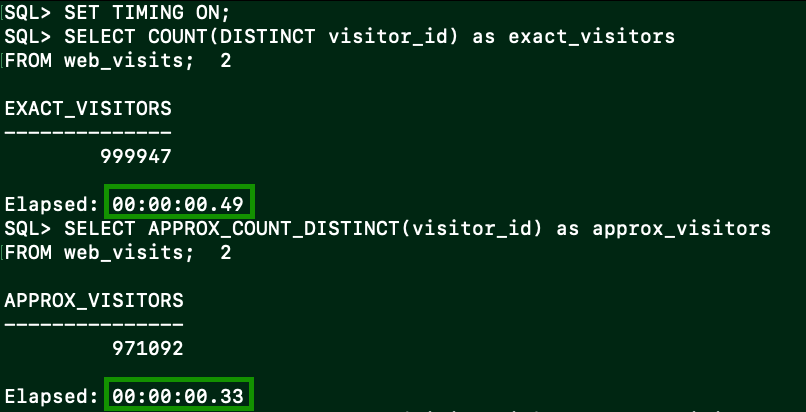
It's faster but the demo is still small.
I have a table with 1.2GB in my database we can look at. This was created using Swingbench, a free load generator / stress test tool.
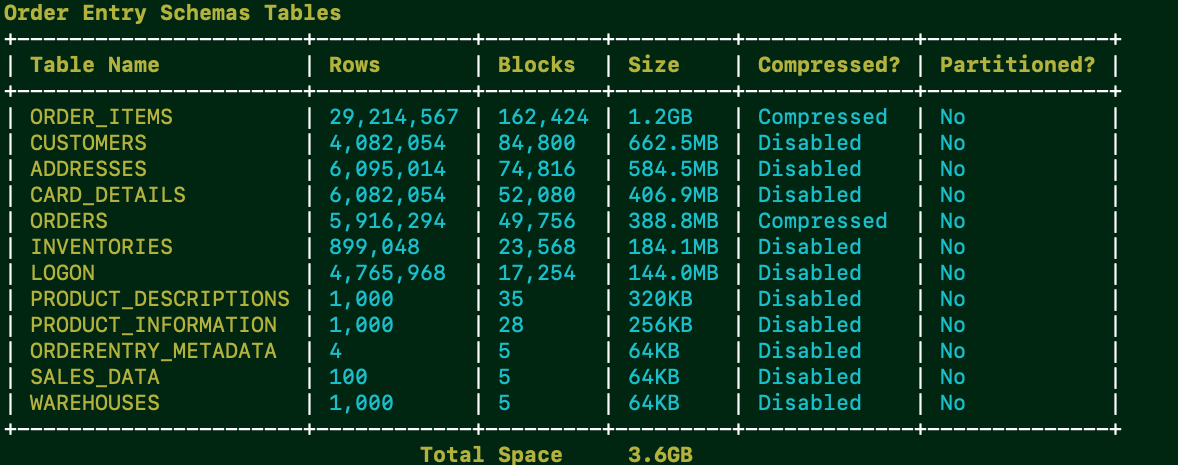
We can look at the exact vs approximate counts here too
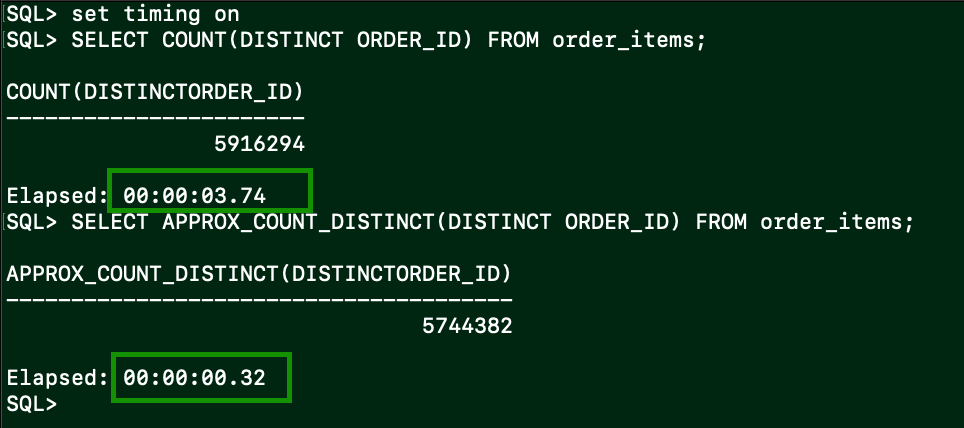
This shows the first query doing an exact count took 3.74 seconds and the approximate count query took .32 seconds.
The approximate count was also 2.89% from the absolute value.
Limitations:
-
Not suitable when 100% accuracy is required (financial calculations, legal reporting)
-
Supports any scalar data type other than BFILE, BLOB, CLOB, LONG, LONG RAW, or NCLOB.
I came across a blog by Christian Antognini where he put together a more in depth test case on how well the function works
Additional Info
-Killian