AI Vector Search in Oracle Database 23ai (alternate title: A Negroni and the Oracle Database ?)
Imagine asking natural language questions against the database and receiving relevant, personalized answers. Oracle Database 23ai’s AI Vector Search makes it possible.
In this blog, we’ll take a high level look at how AI Vector Search works and how you can use it to build smarter, context-aware applications.
How does it work?
At its core, this feature brings together your business data with Large Language Models (LLMs) and allows you to do things like Retrieval Augmented Generation (RAG). RAG combine the structured or unstructured data you have with an LLMs understanding of natural language and context. Oracle Database 23ai makes this possible through its new vector data type and a suite of AI-enhanced SQL functions along with Vector Indexes (which will be covered in another blog).
Let's start by understand the key to it all... Vectors
What Are Vectors?
Vectors are the backbone of modern AI (let's just assume I'm talking about LLMs like ChatGPT, Llama, and Claude when I say AI in this blog) . Think of them as arrays of numbers that represent meaning of data like images, text, audio, and more. For example, a photograph like the one below could be represented something like this:

Just a Negroni, nothing complex.
Vectors help LLMs like OpenAI’s embedding models make sense of complex, unstructured data.
Dimensionality in Vectors
Each vector exists in a space defined by its dimensions, or the number of items in the array. For example, the image above has 70 dimensions. OpenAI’s text-embedding-3-small model creates vectors with 1,536 dimensions. The embedding model you work with will define the number of dimension that your data gets 'mapped' to. (A small aside note, at the time of this writing, Oracle Database 23ai supports vectors up to 64,000 dimensions).
Here’s how vectors are stored and manipulated in Oracle Database:
CREATE TABLE vector_table (
id NUMBER,
v VECTOR
);
INSERT INTO vector_table VALUES (1, '[0.1, 0.2, 0.3]');How do we get Vectors?
V****ectors are generated by embedding models, which turn unstructured data into a machine-readable format.
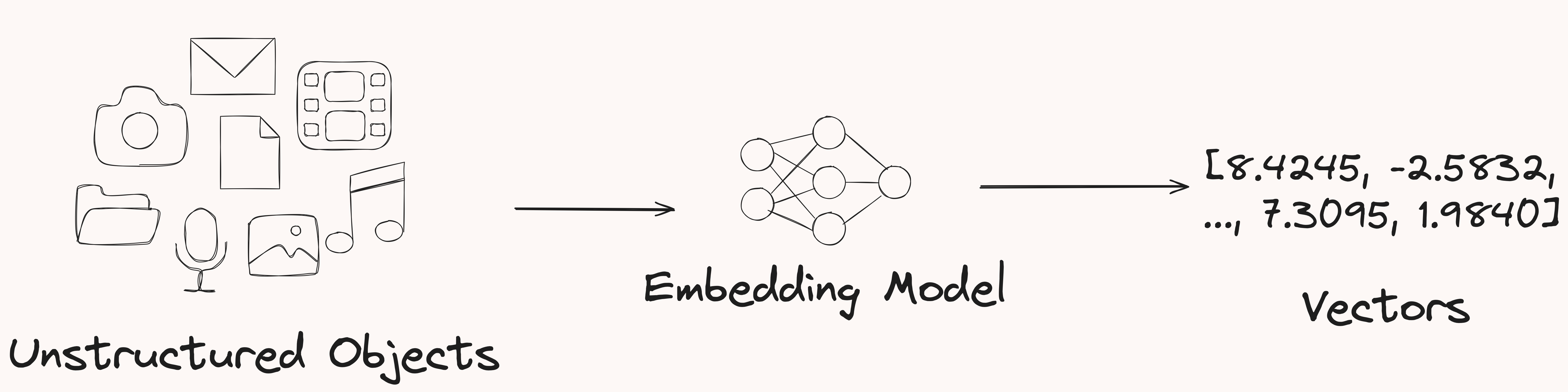
The model you choose depends on your needs—text, images, audio, or even multimodal embeddings. Check out Hugging Face Massive Text Embedding Benchmark (MTEB) Leaderboard to see out some popular text models.
With Oracle Database 23ai, you can load ONNX-format embedding models directly into the database. This offers:
-
Data security: Sensitive data stays inside the database.
-
Efficiency: You can embed data in near real-time as it’s inserted into the database.
Vectors in action
To keep this blog at a reasonable length, let’s explore a simple use case. I’ll cover a full demo example (including loading an embedding model into the database) and building an app in a follow-up blog.
Imagine we’ve got a cocktail application where we can look up step-by-step guides to make different types of drinks. Now, let’s consider how we could improve it to allow users to ask questions in natural language against our dataset.
Setting Up the Database
First, let’s set up a table to store both traditional recipe data and the vector embeddings:
CREATE TABLE cocktail_recipes (
id NUMBER GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
name VARCHAR2(100),
ingredients JSON,
instructions CLOB,
description CLOB,
cocktail_embedding VECTOR
);Notice the cocktail_embedding column—this is where the vectors, representing the “meaning” of the cocktail description, will be stored.
Vectorization of Cocktails
The next step is to pick a pre-trained text embedding model. The model converts the descriptive text for each cocktail into a vector. These vectors turn the cocktails into a machine-readable format.
I’ll go into the specifics of how to load a model into the database in a future post (linked here when ready).
Searching with Vectors
Once the data is stored as vectors, you can create the functionality for natural language searches. Different use cases require different search requirements, whether thats exact, approximate, hybrid, or multi-vector similarity searches. You can learn more about them here.
Oracle AI Vector Search’s native SQL operations allow you to combine similarity searches with traditional relational searches. The SQL function VECTOR_DISTANCE is the key to calculating the distance between two vectors.
Why Is Calculating Distance Between Vectors Important?
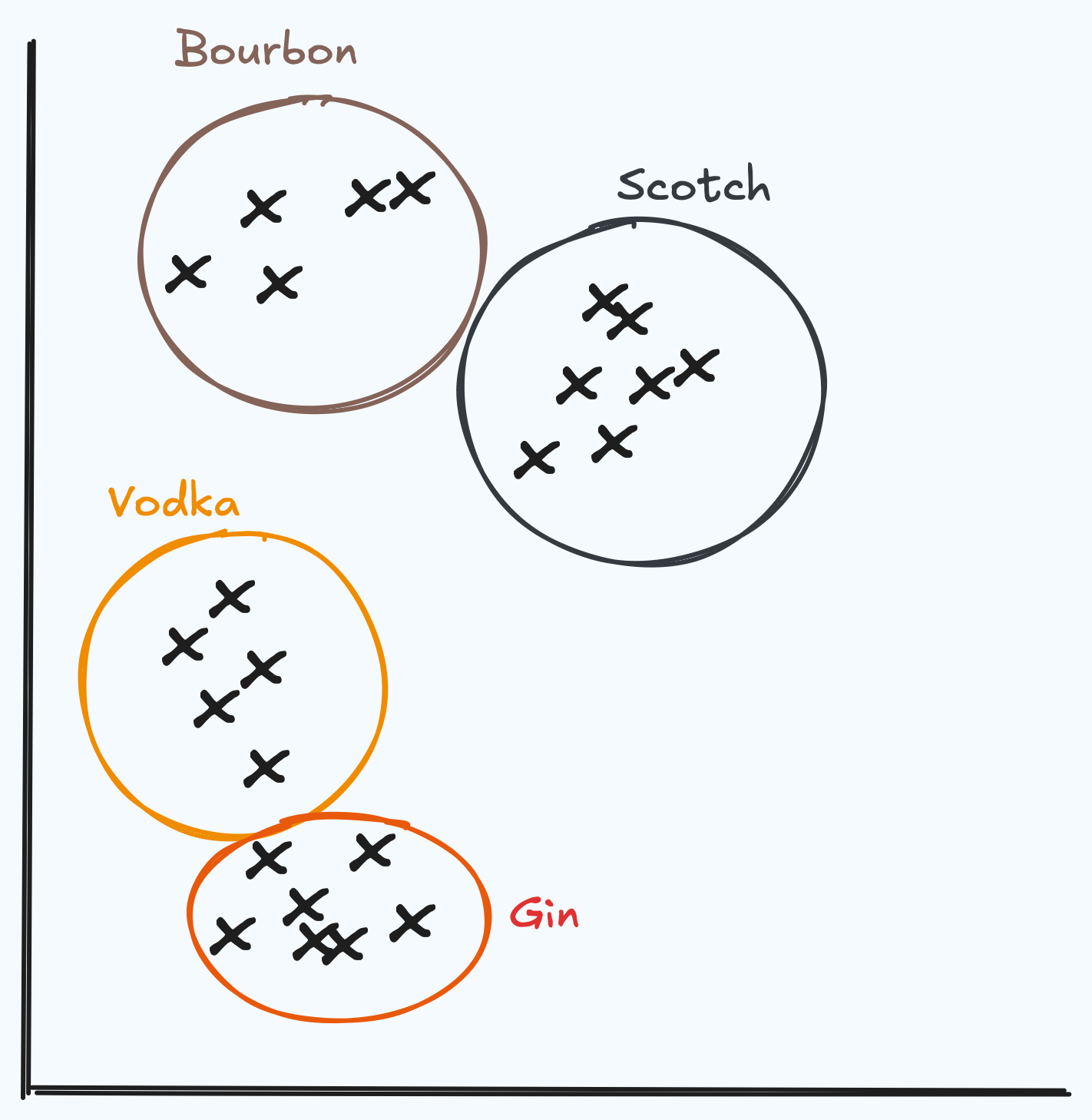
When objects, like cocktail descriptions, are passed through an embedding model, they are represented as vectors in a vector space. What we find is similar vectors group closely together.
Let’s visualize this:
Let's imagine a set of drink descriptions as data points on a graph, reduced to two dimensions so we can plot them
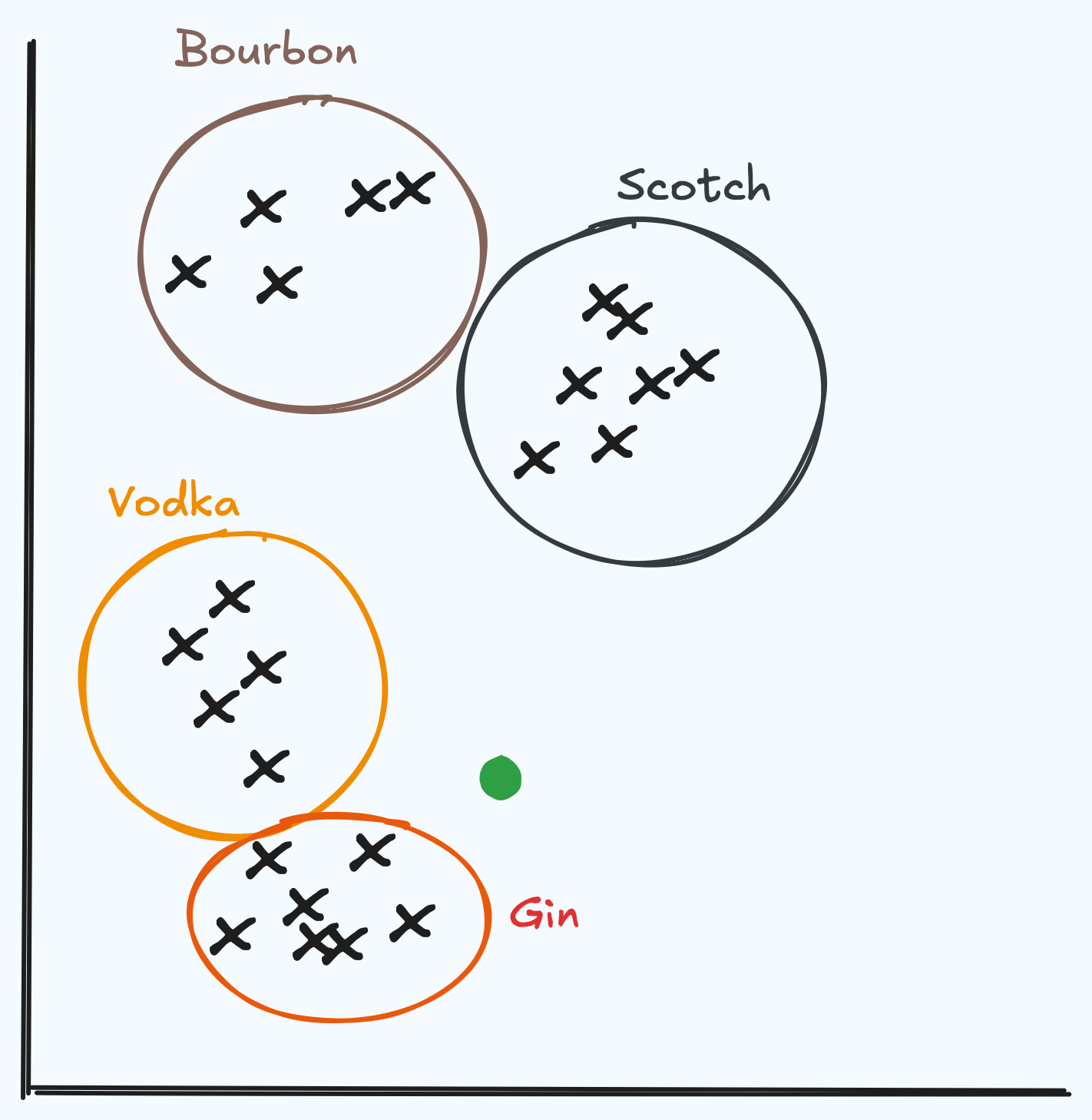
We can take this a step further. Consider a user’s question, (represented by a green dot on the graph below). By finding the distance between the question and the cocktail vectors, we can find the drinks that would be most similar. This lets you take advantage of both the contextual understanding an LLM has, with the application/business data stored inside the Oracle Database.
There are a handful ways to calculate distance and determine how similar, or dissimilar two vectors are. You can learn more about them here.
App Flow: From Input to Results
Here’s how the cocktail app works when a user interacts with it:
-
User Input:
Suppose a user asks: “What's the best summertime drink?”
This is a natural language question—not a keyword-based search. It’s conversational, vague, and personal.
-
Embedding the Query:
The app passes the question through the same embedding model used to vectorize the cocktail descriptions. If you want to analyze user questions later using Oracles built in Database Machine Learning Models, you can store them in a table:
CREATE TABLE IF NOT EXISTS customer_questions (
cust_q_id NUMBER GENERATED BY DEFAULT AS IDENTITY PRIMARY KEY,
id NUMBER,
cust_question CLOB,
cust_q_vector VECTOR,
FOREIGN KEY (cust_q_id) REFERENCES cocktail_recipes(id)
);-
Returning the result:
Use the new VECTOR_DISTANCE function to calculate the similarity between the user’s question vector and the cocktail vectors:
For example:
SELECT c.name, c.description, c.instructions
FROM cocktail_recipes c
CROSS JOIN (
SELECT cust_q_vector
FROM customer_questions
WHERE id = 1
) cq
ORDER BY VECTOR_DISTANCE(c.cocktail_embedding, cq.cust_q_vector, EUCLIDEAN)
FETCH FIRST 4 ROWS ONLY;-
Presenting Results
For a question like “What’s the best summertime drink?”, you might return:
• Negroni: A classic Italian cocktail with gin, vermouth, and Campari. Bittersweet and aromatic.
• Aperol Spritz: A bubbly mix of Aperol, Prosecco, and soda water. Refreshing and perfect for daytime.
Because of AI Vector Search, the database can understand the users intent and gives meaningful results, not just matching words.
So to wrap up, AI Vector Search in Oracle Database 23ai is what allows businesses to benefit from their vast amounts of data, and the capabilities and power of LLMs. In this small example, you can move from keyword searches and basic filters, to actually matching user intent in application. As a result, you get an intelligent, LLM-augmented search that feels more like a conversation than a transaction.
In a future blog, i'll walk through how to build a full application that puts these capabilities into action.
- Killian